How enterprises move from GraphRAG experiments to scalable, trustworthy AI systems
Jakki Geiger, CMO at Arango in conversation with
Ravi Marwaha, Chief Product & Technology Officer at Arango
TL;DR
Graph databases are necessary but not sufficient for enterprise AI.
Modeling relationships in a graph database is not the same as managing business context. As AI systems move from retrieval to reasoning and action, graph-first architectures break because context is fragmented across graph, vector, and operational systems. Reconstructing business context can work in pilots, but it fails in production at scale. Reliable AI requires every agent to operate on the same unified, current, and trusted version of reality. In practice, enterprise AI reflects the data strategy beneath it—and organizations that move beyond graph-only approaches are the ones pulling ahead.
Graph Databases Solved One Problem—Not the Whole One
Graph databases changed how enterprises think about data. By making relationships first-class, they enabled AI systems to move beyond isolated documents and records toward connected representations of customers, products, incidents, and policies.
That shift is foundational. Without graphs, modern AI—especially agentic and reasoning-based systems—simply does not work.
But in practice, many teams are discovering that graph databases solve only part of the enterprise AI problem.
When AI systems leave the lab and enter production, new requirements emerge that relationships alone cannot satisfy:
- What is true right now—and what was true when a decision was made
- Which sources are authoritative and why
- How structured data, unstructured knowledge, and multimodal signals relate to the same entities
- How multiple agents stay consistent as data and policies change
This is where graph-centric architectures begin to strain.
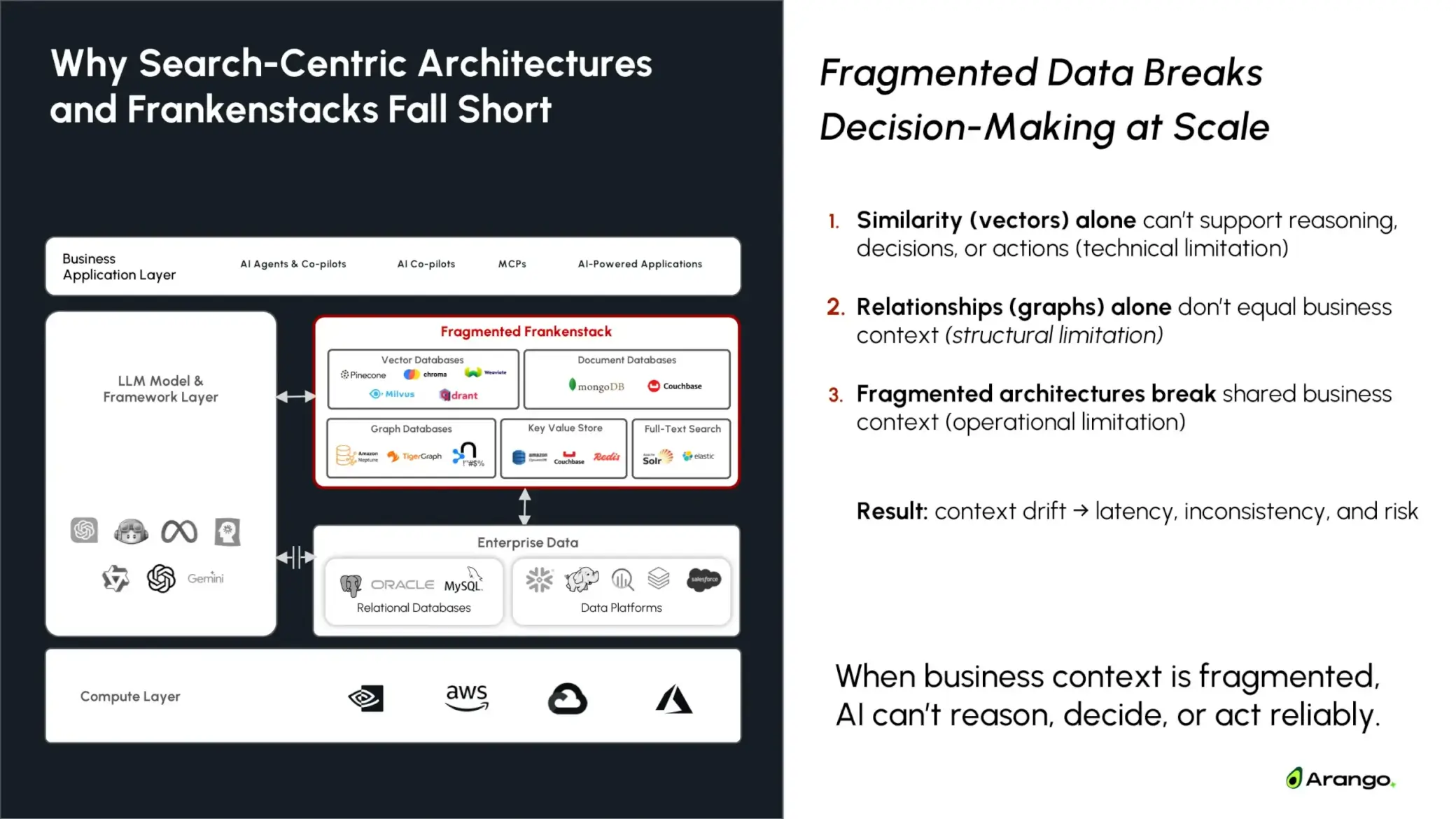
Search-centric architectures and Frankenstacks fragment business context, preventing AI systems from reasoning, deciding, and acting at scale.
Why Graph-Only Architectures Break at Scale
Most enterprise AI stacks combine:
- A graph database for relationships
- A vector database for semantic retrieval
- Document stores, logs, and operational systems elsewhere
- Orchestration code to stitch everything together
On paper, this looks flexible. In reality, it creates a fragile system where business context is reconstructed at runtime.
Each AI agent or co-pilot must:
- Pull data from multiple systems
- Reconcile entity definitions (which customer, which incident?)
- Resolve conflicting or outdated information
- Infer trust and relevance on the fly
This approach works for pilots. It fails as soon as AI becomes mission-critical.
Latency increases. Context logic gets duplicated. Definitions drift. And different agents start operating on different versions of reality.
The core issue isn’t performance—it’s architectural drift caused by fragmented context.
Relationships ≠ Business Context
A common misconception is that modeling relationships is the same as modeling business context. It isn’t.
Relationships explain how things connect. Business context determines:
- Meaning — shared semantics and definitions
- Time — what was true when, not just what is true now
- Trust — where information came from and whether it’s authoritative
- State — current conditions, constraints, and policies
- Evidence — why an AI system reached a conclusion
Graph databases are exceptional at modeling relationships. But, relationships alone aren’t business context. Production AI needs shared meaning, time, trust, and state, and graphs weren’t designed to unify all of that into a contextual datal layer.
That gap becomes visible the moment AI systems are expected to explain decisions, maintain consistency across agents, or take action safely.
Graphs are exceptional at modeling relationships. But relationships alone aren’t business context.
Production AI needs shared meaning, time, trust, and state, and graphs weren’t designed to unify all of that into a contextual data layer.
— Ravi Marwaha, Chief Product & Technology Officer, Arango
Why Orchestration Isn’t Enough
When graph + vector architectures start to strain, teams often respond with more orchestration.
Orchestration connects systems—but it does not create shared understanding.
Instead, complexity moves into application code. Each new agent introduces more pipelines, more glue logic, and more failure modes. Over time, teams end up maintaining a Frankenstack where every change becomes an integration project.
The result is slower delivery, higher operational risk, and declining trust in AI outputs.
Agents Change the Stakes
Retrieval-based AI systems surface information. Agents and co-pilots act.
That distinction matters.
Agents must reason over:
- Structured data for state and rules
- Unstructured data for human knowledge
- Multimodal signals (logs, code, media) to explain what happened
Most importantly, all of this data must be connected to the same underlying entities and definitions. If each agent reconstructs context independently, decisions become inconsistent and confidence collapses.
This is why many enterprise AI initiatives stall—not because models fail, but because the data foundation cannot support shared, trustworthy context at scale.
The Shift: From Graph-First to Context-First
What’s missing isn’t another database. It’s a contextual data layer.
A context-first architecture manages business context once and delivers it consistently to every AI system. It unifies:
- Structured, unstructured, and multimodal data
- Relationships, meaning, time, and provenance
- Retrieval, reasoning, and explainability paths
Instead of rebuilding context for every use case, teams reuse the same trusted foundation.
This shift reduces latency, simplifies architecture, and allows AI capabilities to compound rather than reset with each new project.
When a Graph Database Is Enough
It’s important to be precise.
If your primary goal is graph analytics, relationship exploration, or domain-specific knowledge graphs, a standalone graph database is often sufficient.
The inflection point comes when:
- AI systems must share context across teams and workflows
- Data changes continuously
- Decisions carry operational, regulatory, or financial consequences
At that point, the problem is no longer graph modeling. It’s context management at enterprise scale.
The Bottom Line
Graph databases are a critical foundation for enterprise AI—but they are not the finish line.
As AI systems move from answering questions to taking action, enterprises need more than connected data. They need unified, current, and trusted business context delivered consistently to every agent.
The organizations pulling ahead are the ones making this architectural shift early—moving beyond graph and vector silos toward context-first data platforms built for production AI.
That shift is what turns AI from a series of pilots into a durable competitive advantage.
What’s Next?
The Definitive Guide to Agentic AI-Ready Data Architecture
If you’re actively designing or evolving your AI data stack, this guide breaks down the architectural decisions required to simplify complexity, avoid Frankenstacks, and scale AI with confidence.
Forrester on Multimodel Data Platforms
Read how analysts assess multimodel platforms as enterprises move beyond stitched-together graph and vector systems toward simpler, production-ready AI architectures.
Go Beyond Vector Databases
Understand why retrieval-first approaches break down—and how the need for unified, current, and trusted business context reshapes the AI stack.




