Multi-agent AI is consuming tokens at a pace that is breaking enterprise budgets. This brief shows how combining Arango’s Contextual Data Layer with NVIDIA’s KV-cache infrastructure cuts costs by 66% — without reducing model quality or agent capability.
01 The Agentic Inflection
The Rise of the Agentic Enterprise — and Its Unexpected Tax
We are living through a fundamental shift in how AI systems operate. The first generation of enterprise AI was transactional: one question, one answer, bounded and predictable. The agentic generation is something else entirely. Agents reason across steps, delegate to sub-agents, call external tools, manage their own memory, and decide for themselves when a task is done.
This capability leap is real and it is accelerating. By early 2026, organizations across financial services, healthcare, cybersecurity, and high-tech are deploying multi-agent architectures — systems where a primary agent orchestrates dozens of specialized sub-agents, each capable of reading files, querying databases, writing code, or triggering downstream workflows. The productivity gains are measurable and significant.
But there is an unexpected tax embedded in this new paradigm: token cost.

Multi-agent systems consume up to 15× more tokens than standard chat. The economics that made simple AI deployments viable simply do not scale.
Anthropic’s own research quantified this directly. A single agentic coding session — 33 minutes, one task — generated 283 inference requests, with the context window growing from 15,000 tokens to a peak of 156,000 before a compaction event collapsed it back down. A primary agent coordinating 225 sub-agent invocations accumulated over 4.5 million input tokens in a single working session.
Multiply that by a team of 50 developers. Multiply that by 250 working days. Multiply that by production-grade enterprise deployments across multiple domains. The numbers become very large, very fast — and they have caught many enterprises off guard.
15×
more tokens vs. standard chat
156K
peak context window in single session
283
inference requests in 33 minutes
4.5M
input tokens per session
The challenge is structural. Unlike chatbots where context grows linearly with conversation, agentic systems behave with what NVIDIA describes as “structurally probabilistic” token consumption. Each tool call injects its output directly into the context window. Each sub-agent spawns its own context. Each delegation creates a new token surface. The result is a workload that is orders of magnitude more expensive — and far harder to predict or budget.
For enterprises moving from AI experimentation to production, this is not a theoretical problem. It is a budget line item that can make or break the business case for agentic AI at scale.
What is a Context Window?
A context window is the maximum amount of text — measured in tokens — that an AI model can read and process in a single inference call.
Think of it as the model’s active working memory: it includes the system prompt, user messages, conversation history, retrieved documents, and tool outputs. Everything the agent needs to reason over must fit inside this window. Once the window fills up, older content must be dropped or compacted.
Why it matters for agentic AI:
Precision retrieval — delivering only relevant context — keeps windows lean, costs low, and reasoning quality high.
- Every token costs money — larger windows mean higher inference costs.
- Agentic systems grow context windows far faster than chatbots — each tool call, sub-agent response, and retrieved document adds tokens.
- When the window approaches its limit, a compaction event forces the model to summarize and discard content — losing nuance and invalidating cached tokens.
02 The Cost Reality
Doing the Math: What Multi-Agent AI Actually Costs
To understand the scale of this challenge, let’s build a concrete cost model for a realistic enterprise deployment — a team of 25 AI agents performing continuous research, analysis, and workflow automation tasks across an organization.
Baseline Assumptions
Model pricing reference: Input tokens at $3.00/1M (uncached) · $0.30/1M (cached) · Output tokens at $15.00/1M. Represents frontier-model API pricing tiers typical in mid-2026 enterprise contracts.
Scenario A — Conventional Multi-Agent Stack (No Optimization)
| Variable | Value | Notes |
|---|---|---|
| Active agents | 25 | Concurrent, production agents |
| Avg requests / agent / day | 320 | Based on NVIDIA session data extrapolated |
| Avg input tokens / request | 42,000 | Mix of short sub-agent and long main-agent contexts |
| Avg output tokens / request | 1,200 | Standard agent response generation |
| Cache hit rate | 40% | Poor — fragmented retrieval, no stable prefix |
| Working days / year | 250 |
Annual Token Cost Calculation — Conventional Stack
| Cost Component | Tokens / Year | Rate | Annual Cost |
|---|---|---|---|
| Uncached input tokens (60%) | 50.4B | $3.00 / 1M | $151,200 |
| Cached input tokens (40%) | 33.6B | $0.30 / 1M | $10,080 |
| Output tokens | 2.4B | $15.00 / 1M | $36,000 |
| Total Annual Token Cost | 86.4B tokens | $197,280 |
Nearly $200K per year in pure token costs for 25 agents — before infrastructure, hosting, human oversight, or integration maintenance.
Without addressing the underlying data architecture problem, token costs scale linearly — or worse — as agent complexity grows.
The deeper issue is why the cache hit rate stays so low in a conventional stack. When agents must reconstruct relationships during inference — fetching from vector stores, re-querying databases, re-assembling enterprise context on every request — the input token sequence changes unpredictably. A changing prefix means the KV cache can’t reuse prior work. Every token looks new. Every request pays full price.
03 Root Cause
Why Conventional Stacks Fail at Scale
The conventional enterprise AI stack is what Arango calls a “Frankenstack” — multiple disconnected systems bolted together: a vector database for semantic search, a graph database for relationships, a relational database for structured records, a document store for knowledge, and various retrieval pipelines stitching them together. Each system was designed independently, and none of them were designed to serve the needs of an AI agent reasoning across all of them simultaneously.
Architecture Comparison
What Goes Wrong — Conventional Stack
What’s Needed — Optimized Architecture
Every reconnection between agent and data store represents token spend. Each sub-agent independently queries multiple disconnected stores, reassembles context from scratch, and injects that reconstructed context into its window — creating an unstable, ever-changing token prefix that the KV cache cannot reliably reuse.
The three core failure modes of conventional stacks:
- Multi-hop retrieval tax — Each sub-agent queries 4–5 separate data stores per request. The combined volume of retrieval output, injected into the context window, accounts for 40–60% of average input tokens.
- Cache prefix instability — Because each retrieval returns slightly different results, the KV cache cannot establish a stable prefix. Cache hit rates stay below 50%, meaning the majority of input tokens must be fully reprocessed at full cost.
- Compaction cascade cost — Context rot forces compaction events that collapse the context window — but also invalidate cached tokens. Each compaction event creates a spike of uncached input tokens that must be reprocessed from scratch.
04 The Architecture
Two Layers, One Solution: Arango + NVIDIAle
The answer to the billion-token problem requires attack from two directions simultaneously. NVIDIA’s KV-cache infrastructure addresses how tokens are served and reused at the compute layer. Arango’s Contextual Data Platform addresses what enters the context window in the first place. Together they are complementary — and together they close the economic gap that neither can close alone.
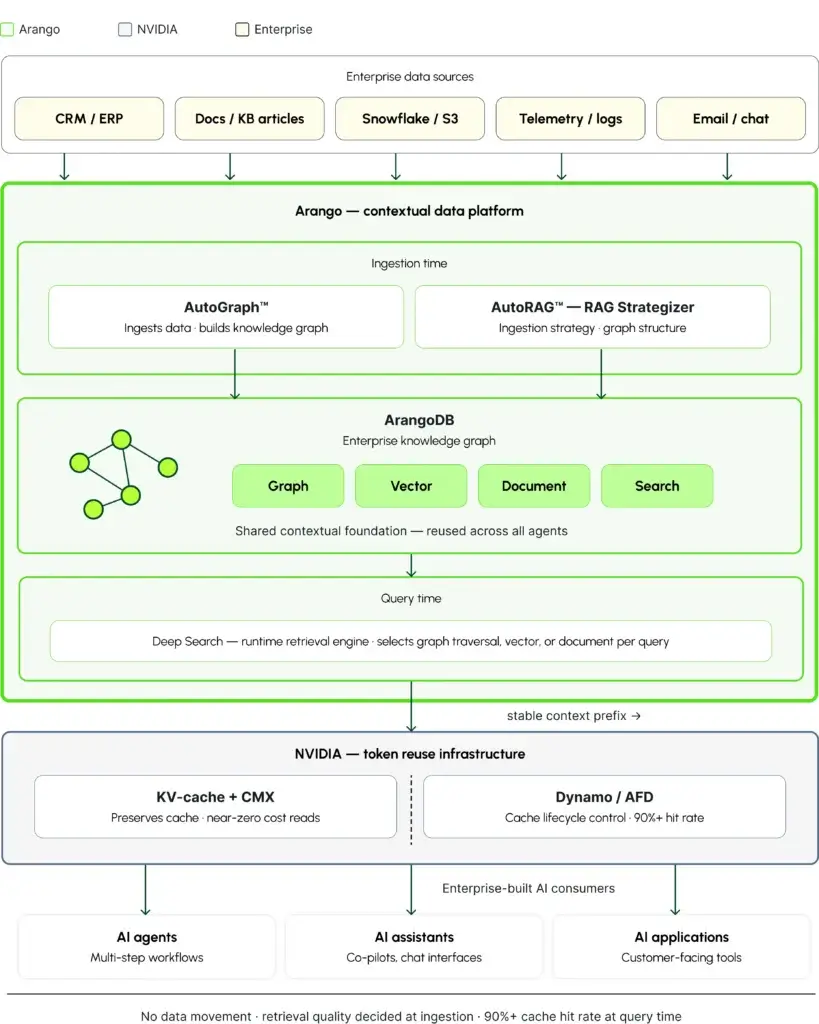
Understanding the Architecture: A Reader’s Guide
Enterprise AI doesn’t fail because of bad models. It fails because of bad data architecture — and nowhere is that more expensive than in multi-agent AI systems, where token costs compound with every tool call, every sub-agent delegation, and every context reconstruction.
The architecture below maps the journey from raw enterprise data to a governed, cost-efficient AI response — and shows exactly where Arango and NVIDIA each play their role. The flow reads top to bottom across five layers.
Enterprise data sources
It begins with your existing enterprise data — CRM records, knowledge base articles, Snowflake warehouses, telemetry logs, email threads. This data doesn’t move. It stays where it lives.
Ingestion time — AutoGraph™+ AutoRAG™
Two Arango components work at ingestion time. AutoGraph™ ingests that data and automatically constructs a unified knowledge graph — capturing relationships between entities, events, and business rules so no agent ever reconstructs them at query time. AutoRAG™ acts as the RAG Strategizer: it determines the optimal ingestion strategy and graph structure upfront, ensuring the knowledge graph is retrieval-ready before a single query is ever asked.
ArangoDB — the knowledge graph
At the center sits ArangoDB — a single multi-model engine combining graph traversal, vector search, document retrieval, and full-text search. This eliminates the Frankenstack of disconnected stores that forces agents to make four or five data calls per request. Because this knowledge graph is shared, every agent — regardless of function — draws from the same trusted, current foundation.
Query time — Deep Search
At query time, Deep Search takes over as Arango’s runtime retrieval engine. It scans the knowledge graph and dynamically selects the right retrieval strategy for each query — graph traversal, vector search, or document retrieval — returning precisely the context the agent needs, not everything it could possibly find. This precision produces a stable, predictable context prefix.
NVIDIA — token reuse infrastructure
That stable prefix is what makes NVIDIA’s infrastructure decisive. KV-cache + CMX preserves context memory across long sessions and multi-agent interactions. Dynamo/AFD gives the agent harness direct control over cache lifecycle, sustaining hit rates above 90% and driving per-token input costs down by 85% or more.
Enterprise-built AI consumers
The result flows to the enterprise-built AI consumers — agents, assistants, and applications — owned and operated by your organization, not by Arango or NVIDIA. They receive faster, more accurate, more consistent responses built on a governed, auditable, always-current data foundation.
The key insight the architecture makes visible: Arango governs what enters the context window — and ensures it is structured correctly before any query runs. NVIDIA governs how those tokens are processed and reused once they arrive. Neither can close the economic gap alone. Together, they reduce token costs by 66% without touching model quality or agent capability.
Solution Architecture
Component Reference
| Vendor | Component | What It Does |
|---|---|---|
| Arango | AutoGraph™ | Pre-builds entity relationships in a unified knowledge graph so agents query once and receive complete relational context — no inference-time reconstruction. |
| Arango | AutoRAG™ | Determines the optimal ingestion strategy and graph structure for your data — so retrieval quality is decided at ingestion time, before a query is ever asked. This is not runtime retrieval selection. |
| Arango | Deep Search | The runtime retrieval engine. Scans topics across the knowledge graph and dynamically selects the right retriever — graph traversal, vector search, or keyword — for each query. Returns the most relevant context, not just the nearest match. |
| Arango | ArangoDB Multi-Model | Unifies graph, vector, document, and search in a single platform — eliminating the multi-hop retrieval that destroys cache efficiency. |
| NVIDIA | CMX | High-capacity, purpose-built storage that preserves KV cache entries across long sessions and multi-agent interactions. |
| NVIDIA | Dynamo / AFD | Gives the agent harness direct control over cache lifecycle — ensuring stable Arango-produced prefixes are retained and restored efficiently. |
| NVIDIA | Vera Rubin NVL72 | Keeps shared context accessible at low latency across the full multi-agent fleet via NVLink 6 fabric. |
The key insight in this architecture is the separation of concerns. Arango governs what enters the context window — and when it does. AutoGraph builds the knowledge graph. AutoRAG determines the optimal ingestion strategy and graph structure. Deep Search selects the right retriever at runtime. NVIDIA governs how those tokens are processed and reused. Neither system is aware of the other’s implementation — they are joined by the stable, predictable structure of the context Arango produces.
05 How it Works
Layer by Layer: What Each Component Does
AutoGraph™ — Pre-Build Relationships [ARANGO]
Automatically ingests enterprise data and constructs a unified knowledge graph representing entity relationships, operational states, and business rules. Agents query the graph instead of reconstructing relationships at inference time — eliminating the most expensive source of context bloat.
AutoRAG™ — Ingestion Strategy & Graph Structure [ARANGO]
Automatically determines the optimal ingestion strategy and graph structure for your data — so retrieval quality is decided at ingestion, not at query time. AutoRAG is the RAG Strategizer: it ensures your knowledge graph is structured correctly before any query is ever asked, eliminating the need for constant RAG pipeline retuning as data evolves.
Note: AutoRAG governs ingestion and graph structure — not runtime retrieval selection. Runtime retrieval is handled by Deep Search.
Deep Search — Runtime Retrieval Engine [ARANGO]
Deep Search is the runtime retrieval engine of the Arango Agentic AI Suite. It scans topics across the knowledge graph and dynamically selects the right retriever — graph traversal, vector search, or document retrieval — for each query. Rather than returning the nearest match, Deep Search finds the right answer by reasoning across connected enterprise knowledge. This is the component that selects optimal retrieval strategies at query time — not AutoRAG.
ArangoDB Multi-Model — One Store [ARANGO]
Graph, vector, document, and search in a single system. Eliminates the multi-hop retrieval across disconnected stores that creates unpredictable context prefixes and destroys cache efficiency. One query surfaces complete relational context.
KV-Cache + CMX — Reuse Tokens [NVIDIA]
High-capacity, purpose-built context memory that preserves KV cache entries across long sessions and multi-agent interactions. When Arango delivers a stable prefix, CMX ensures it stays cached — turning every subsequent agent request that shares that prefix into a near-zero-cost cache read.
Dynamo / AFD — Cache Programmability [NVIDIA]
Gives the agent harness direct control over cache lifecycle management. Combines with Arango’s predictable context structure to sustain cache hit rates above 90% — the threshold at which per-token input costs fall by 85% or more.
Shared Contextual Foundation [JOINT]
Because Arango’s Contextual Data Layer is reusable across agents and applications, multiple agents share the same underlying knowledge graph. This means their context prefixes converge — dramatically multiplying the value of every cached token across the entire multi-agent fleet.
06 The New Economics
The Math After Optimization: Scenario B
Let’s return to the same 25-agent enterprise deployment and model what happens with the integrated Arango + NVIDIA architecture in place. Same agents, same task complexity, same working days. Very different economics.
What Changes
Three structural improvements combine to reshape the cost curve:
- Smaller context injections. Deep Search’s precision retrieval reduces the average input tokens per request by approximately 35–45%, because agents receive only the relevant subgraph rather than broad document dumps. Average input tokens drop from 42,000 to approximately 24,000.
- Higher cache hit rate. A stable, predictable context prefix from Arango’s Contextual Data Layer — structured at ingestion by AutoRAG — combined with NVIDIA’s CMX infrastructure, sustains cache hit rates of 90–95%. The improvement from 40% to 92% is the single largest cost lever.
- Reduced compaction frequency. More precise context means slower context growth, which means fewer compaction events. Each avoided compaction event eliminates a costly cache-invalidating spike of uncached input tokens.
Cache economics: API providers discount cache hits by ~90%. At 92% cache hit rate vs 40%: the effective cost per input token falls from $1.92/M to $0.54/M — a 72% reduction in input costs before counting the smaller context size.
Scenario B — Arango + NVIDIA Integrated Architecture
| Variable | Before | After | Change |
|---|---|---|---|
| Avg input tokens / request | 42,000 | 24,000 | −43% |
| Cache hit rate | 40% | 92% | +52pp |
| Compaction events / session | 2.1 avg | 0.6 avg | −71% |
| Effective $/M input tokens | $1.92 | $0.54 | −72% |
Annual Token Cost — Scenario A vs Scenario B
| Cost Component | Scenario A | Scenario B | Savings |
|---|---|---|---|
| Uncached input tokens | $151,200 | $22,464 | $128,736 |
| Cached input tokens | $10,080 | $7,488 | $2,592 |
| Output tokens | $36,000 | $36,000 | — |
| Total Annual Cost | $197,280 | $65,952 | −$131,328 (66%) |
A 66% reduction in token costs for 25 agents. For 100 agents, that is over $500K in annual savings — from architectural choices alone, with no reduction in model quality or agent capability.
07 Strategic Value
Beyond Cost: What This Architecture Enables
The economic argument is compelling on its own. But the deeper value of this architecture is what it unlocks for the enterprise beyond token bill reduction.
Higher Agent Quality, Not Just Lower Cost
Agents operating on Arango’s pre-built knowledge graph make better decisions. They are grounded in unified, current, and trusted enterprise context rather than isolated document retrieval. Arango cites a 20–35% improvement in AI decision accuracy with contextual graph grounding. Fewer hallucinations, fewer incorrect tool calls, fewer costly agent failures that require human intervention.
Eliminating the Context Rot Tax
NVIDIA identifies “context rot” — the degradation of output quality as context windows grow — as a fundamental challenge. Arango’s Deep Search addresses this by keeping context windows lean and relevant through precision retrieval. AutoRAG ensures the knowledge graph is structured for lean, accurate retrieval from the start. Smaller windows mean slower growth, later compaction events, and fewer of the quality degradation cycles that force agent restarts.
Reusable Context Across the Enterprise
One of the most powerful economic effects of Arango’s Contextual Data Platform is the build-once, reuse-everywhere principle. The same contextual knowledge graph that powers a customer service agent can power a fraud detection agent, a compliance agent, and an engineering assistant — all sharing the same underlying context and benefiting from shared KV cache prefixes. Each new agent use case becomes incrementally cheaper to run.
Production Readiness and Governance
Enterprise AI deployments that reach production require more than cost efficiency. They require governance, auditability, and policy enforcement. Arango’s Platform Suite provides RBAC, fine-grained access control, and traceable lineage for every piece of context an agent accesses. This is what separates experimental deployments from enterprise-grade production systems.
Infrastructure Simplification
Replacing a five-system Frankenstack with a unified Arango platform reduces integration complexity by 30–50% and AI development cycles by 2–4×. Every engineer-hour saved on data pipeline maintenance is an engineer-hour redirected toward building the agentic capabilities that deliver business value.
Business Value Summary
| Impact | Outcome | How |
|---|---|---|
| 66% | Token cost reduction | Deep Search precision retrieval + 90%+ KV cache hit rate combined |
| 35% | Better AI decision quality | Agents grounded in unified, current enterprise context via AutoGraph |
| 4× | Faster AI development | Build context once via AutoRAG ingestion strategy; reuse across all agent use cases |
| 50% | Less integration complexity | Unified multi-model platform replaces 5-system stacks |
Ready to reduce your token costs?
Build multi-agent AI that scales without breaking the budget
Arango’s team works with enterprise AI architects to design contextual data layers tailored to your agent workloads, existing data infrastructure, and cost targets.
