Enterprise AI is entering a new phase.
We are no longer experimenting with chat interfaces and copilots that summarize content.
We are deploying agents — systems expected to reason across data, make decisions, and trigger actions in real workflows.
That shift changes everything.
In our recent webinar, “The Missing Layer in the AI Stack,” I was joined by guest speaker Indranil Bandyopadhyay, Principal Analyst at Forrester, to discuss what must change architecturally as AI moves from answering questions to taking action.
One statistic from Forrester framed the conversation:
Only 15% of organizations achieved a positive bottom-line impact from AI in the last 12 months.
As AI systems become more autonomous, that number must improve.
Agents Raise the Bar
A retrieval system can return relevant documents.
A copilot can generate a draft.
An agent must do more:
- Understand business relationships
- Evaluate constraints and permissions
- Interpret current state
- Decide what should happen next
- Execute or trigger action
As Indranil stated:
“Unified, current, and trusted business context is needed for AI that must reason, decide, and act in real-time with confidence.”
This is not optional for agentic AI.
It is foundational.
Why Traditional Architectures Break
Most enterprise stacks were designed for analytics — not autonomy.
Relational databases. Warehouses. Lakes. Search engines. Vector stores. Pipelines connecting them all.
As Indranil emphasized:
“Traditional, stitched data architectures are brittle for AI.”
They may support retrieval.
They struggle with reasoning.
They break when systems must decide and act in real time.
When graph, vector, document, and search systems operate separately — each scaling differently, each governed independently — agents are forced to reconstruct context at query time.
That is fragile, slow, and expensive.
And in high-stakes environments, it is risky.
The Architectural Inflection Point
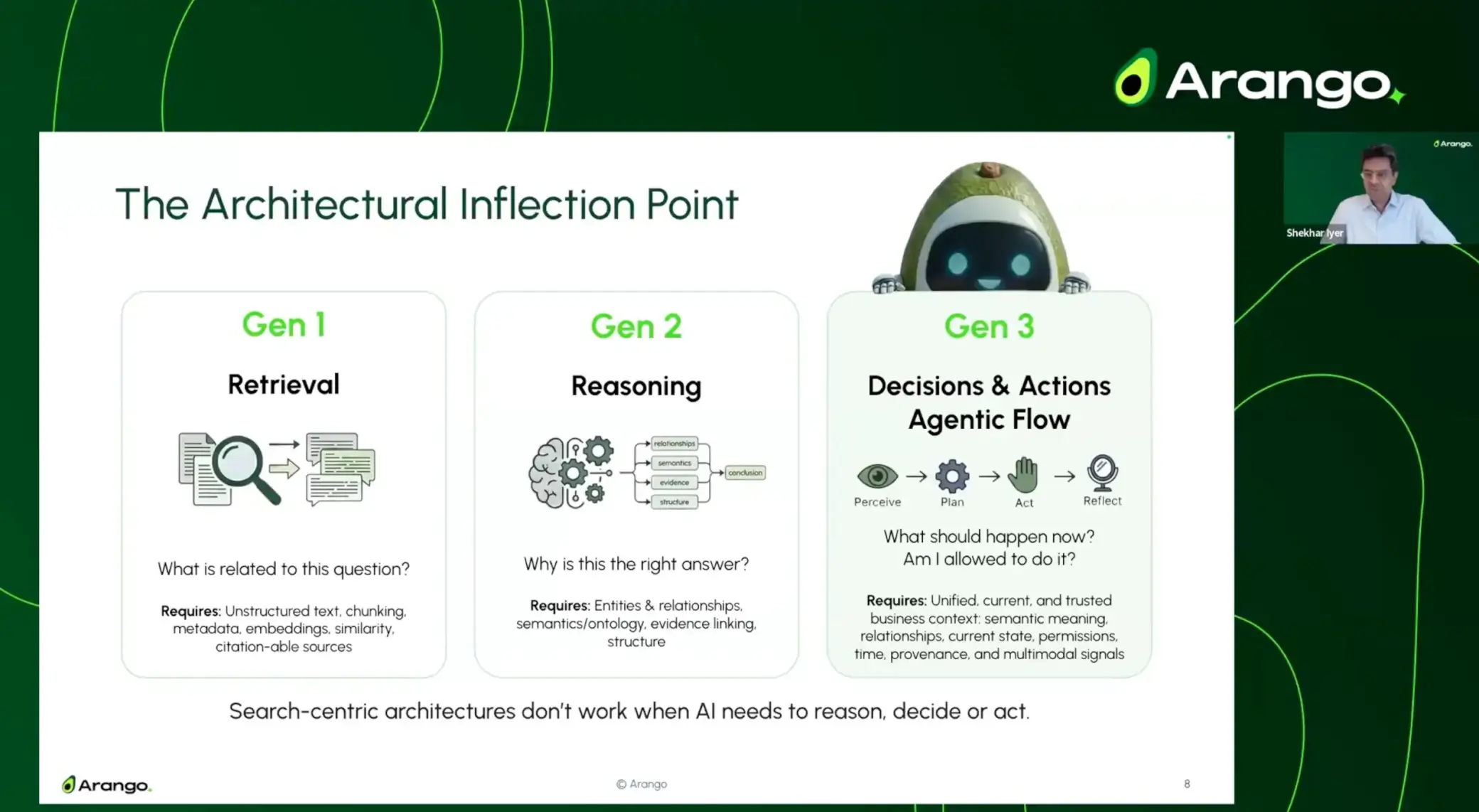
In the webinar, I outlined the progression clearly:
Gen 1: Retrieval
What is related to this question?
Search-centric architectures retrieve similar content — but similarity alone can’t determine relevance, causality, or current state.
Challenge:
Retrieved results often lack relationships, dependencies, or validity in the present business context.
Gen 2: Reasoning
Why is this the right answer?
AI must understand entities, relationships, timelines, and evidence across systems. Traditional pipelines attempt to reconstruct this context downstream.
Challenge:
Stitched pipelines introduce complexity, latency, and gaps in provenance, governance, and temporal accuracy.
Gen 3: Decisions & Actions (Agentic Flow)
What should happen now? Am I allowed to do it?
Agents must act — requiring awareness of permissions, dependencies, and current system state.
Search-centric architectures were never designed for this.
Agents operate in Gen 3.
That requires something fundamentally different:
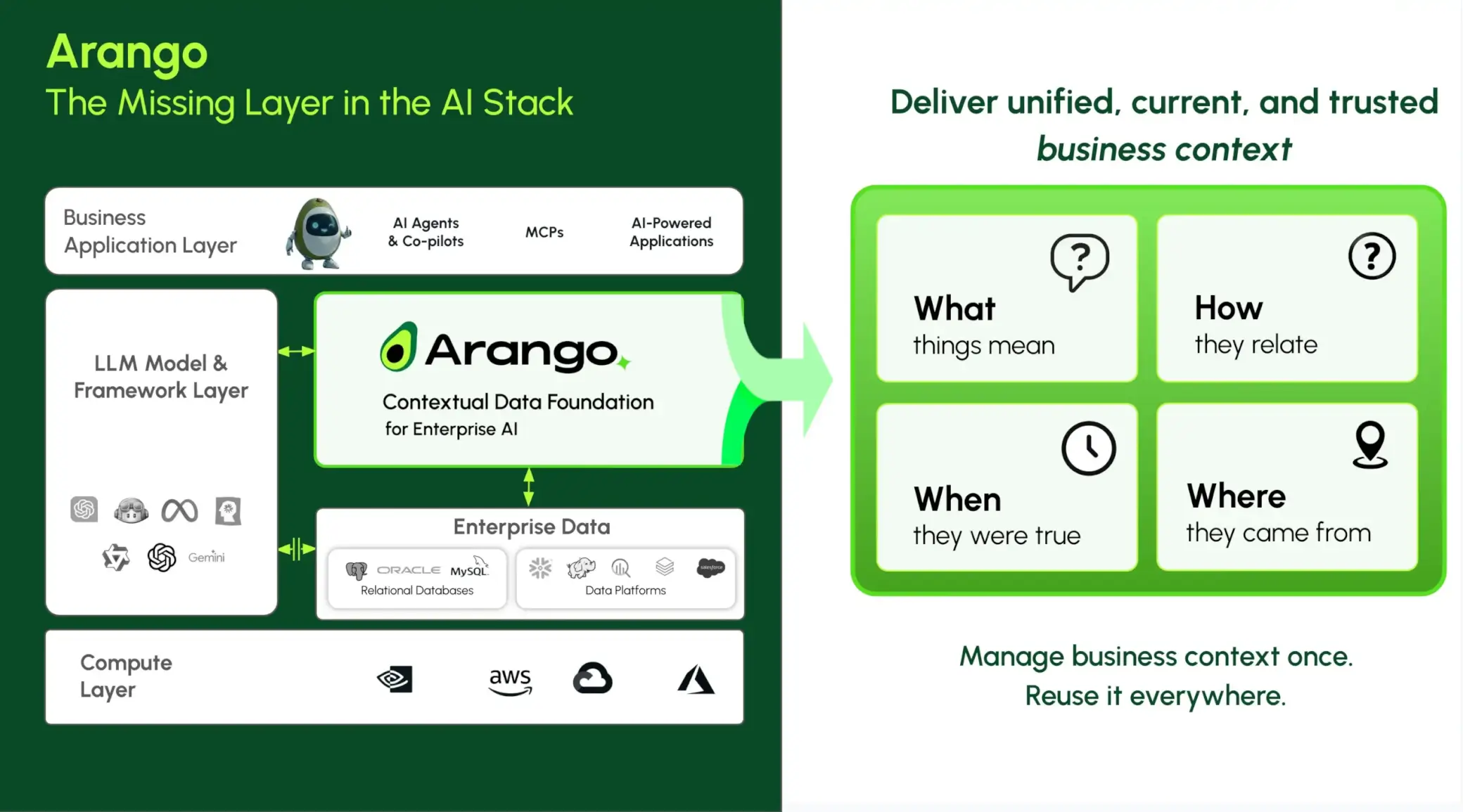
a unified Contextual Data Layer that brings together relationships, semantics, time, permissions, and provenance.
In other words:
- Similarity is easy.
- Reasoning requires context.
- Action requires trust.
What This Means for Enterprise Leaders

As a practical example, Arango’s Service and Support Co-Pilot applies RAG patterns across multimodel enterprise data—including structured system metrics, semi-structured logs, and unstructured trouble tickets and knowledge base content—to help IT operations teams diagnose and resolve incidents more efficiently.
By correlating infrastructure relationships, historical incidents, and live telemetry within a governed contextual layer, the co-pilot can identify root causes across interdependent services and surface relevant remediation steps in real time. Through natural-language interaction with operational data, support engineers can investigate issues, validate recommended actions, and accelerate resolution within established policy controls.
This expands the role of AI agents and co-pilots from information retrieval to operational support—enabling them to:
- Recommend remediation steps based on correlated incident and service context
- Trigger policy-approved workflows for investigation or containment
- Propose configuration changes for review and validation
- Surface risk-aware actions aligned to operational constraints
- Respond to real-time signals within human-guided decision frameworks
To support these capabilities in production environments, the underlying architecture must provide:
- Real-time awareness of operational state
- Relationship-aware access to enterprise data
- Governance controls that establish trust
- Scalable performance across multimodel workloads
A Contextual Data Layer is what enables this.
Without it, agents introduce operational risk, acting on incomplete, outdated, or ungoverned information.
With it, enterprises can move confidently toward production-grade autonomy.
What You’ll Hear in the On-Demand Webinar

For those who missed the live discussion, the on-demand webinar covers:
- Why agentic AI exposes architectural weaknesses
- Where traditional RAG approaches fall short
- What “production-ready, decision-ready, and audit-ready” AI truly requires
- How to evaluate whether your current data stack can support agents
- The architectural decisions that separate experimentation from enterprise impact
This is a strategic conversation grounded in Forrester research and enterprise deployment realities.
The Next Phase of Enterprise AI
The first phase of enterprise AI helped teams work faster.
The next phase integrates AI into production operations with context, trust, and human-in-the-loop control.
Enterprises that build a strong Contextual Data Layer will enable agents that reason, decide, and act with confidence.
Those that rely on stitched architectures will find scale, governance, and trust increasingly difficult to maintain.
If you are responsible for AI strategy, platform architecture, or data infrastructure, I encourage you to access the on-demand session and evaluate what may be missing in your stack.