Chapter 3
The 6 requirements your contextual data layer must deliver
The 6 operating requirements of a contextual data layer: semantic clarity, relationships, freshness, provenance, an AI-native service layer, and unified multimodel coverage.
01
Data carries meaning, not just structure. Canonical entities resolve terminology drift across CRM, billing, and support.
02
Connections between entities are first-class and native. Multi-hop reasoning without federated joins.
03
Context reflects what is true now — and can answer what was true at time T. Bi-temporal by design.
04
Lineage, RBAC, and audit logging embedded in the platform. Every AI output is traceable to source.
05
Retrieve, rank, cite, and ground are built-in. Not reimplemented in every consuming application.
06
Graph, vector, document, key-value, and search — one foundation, one query language, one governance model.
Requirement 01
Semantic clarity
Schemas capture structure. They don’t capture meaning.
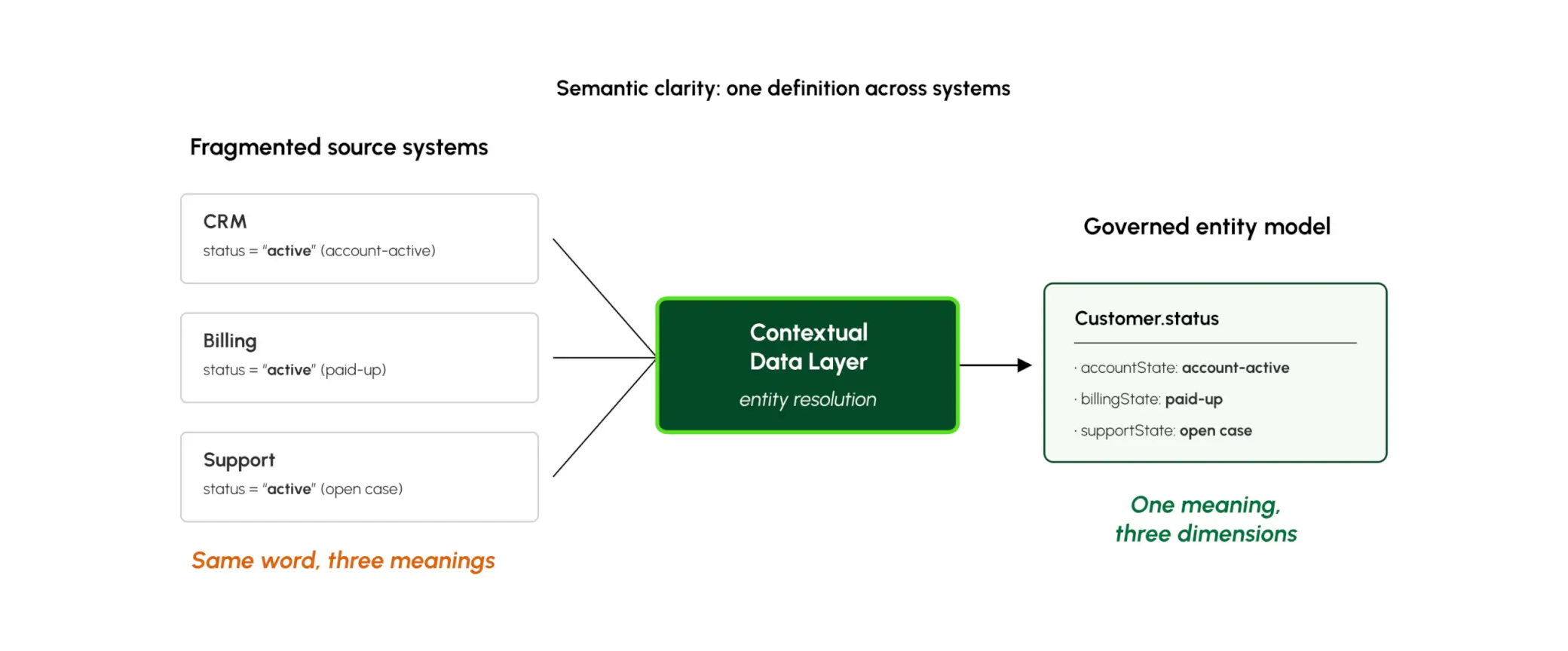
Your schema does not capture what your data actually means. The CRM says “active”; billing says “paying”; support says “green.” Same word, three definitions, three consuming systems.
CRM
status = "active"
= logged-in in last 30 days
Billing
status = "active"
= invoice paid this cycle
Support
status = "active"
= open case
A contextual data layer resolves those definitions into a single shared meaning: one answer to “what does active mean,” applied consistently across every system that asks.
What this gives you
One shared definition for every entity, across every system
Business meaning that stays current as the organization evolves
Consistent answers to the same question, every time
In Arango
AutoGraph automatically builds a knowledge graph that understands your business domain
AQL queries graph, vector, document, and key-value in a single statement — no translation between systems
Definitions and relationships update continuously — no manual re-modeling required
 Failure mode
Failure mode
Every consuming system invents its own join key. The same customer is cust_3781 in CRM, acme-corp in billing, and ACME Corporation, Inc. in support tickets.
AI agents operating on one slice cannot reason across the others without a brittle mapping table that drifts the moment a system changes, a new source appears, or someone enters data differently.
 How Arango solves it
How Arango solves it
Arango resolves those fragmented identifiers into a single, stable entity, automatically. Whether a match is exact, approximate, or inferred from structural similarity, the result is one customer, one ID, one definition that every agent and application reads from. And when definitions evolve (because they always do), Arango tracks those changes over time. A query about what was true last quarter returns last quarter’s answer. A query about today returns today’s.
Requirement 02
Relationships & entity graph
Enterprise context must be connected, not fragmented.
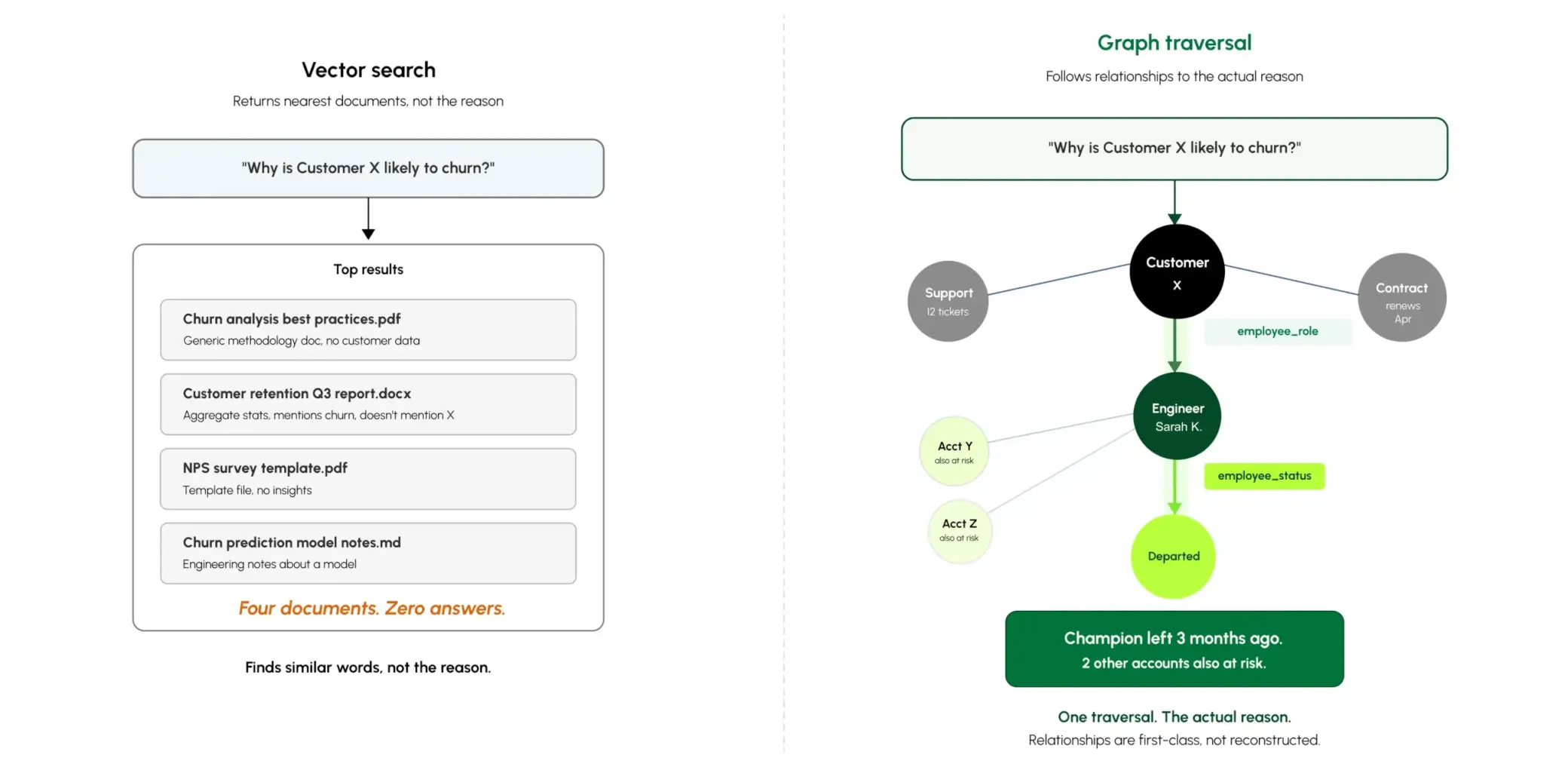
Vector similarity finds related documents. It will not tell you that Customer X is churning because the engineer who championed them left three months ago. That’s a relationship question — and relationships need to be first-class, native edges, not joins invented at query time.
What this gives you
Multi-hop reasoning at query time, not pre-computed
Pattern detection across the entity graph
Path explanations attached to every answer
In Arango
Graph, document, and vector data unified in one store. No joins across systems
AutoGraph continuously builds and maintains the entity graph as your data changes
GraphRAG retrieves answers by traversing relationships, not just matching text
Failure mode
Relational and vector-only stacks flatten relationships into text chunks or join tables. A 3-hop question like “which customers depend on services owned by people who left in the last quarter?” becomes a chain of manual workarounds: complex SQL, repeated fetches, or similarity re-ranking.
Each approach is brittle, built for one query shape, and breaks quietly the moment the underlying data structure changes.
How Arango solves it
Arango stores relationships natively, not as join tables or text approximations, but as direct connections between entities.
That means a multi-hop question traverses the graph in milliseconds rather than executing a chain of joins. And because relationships carry their own attributes (type, weight, time period), a single query can ask not just who is connected, but how, when, and under what conditions.
Requirement 03
Freshness & temporal correctness
Context must reflect what is true now — and what was true at time T.
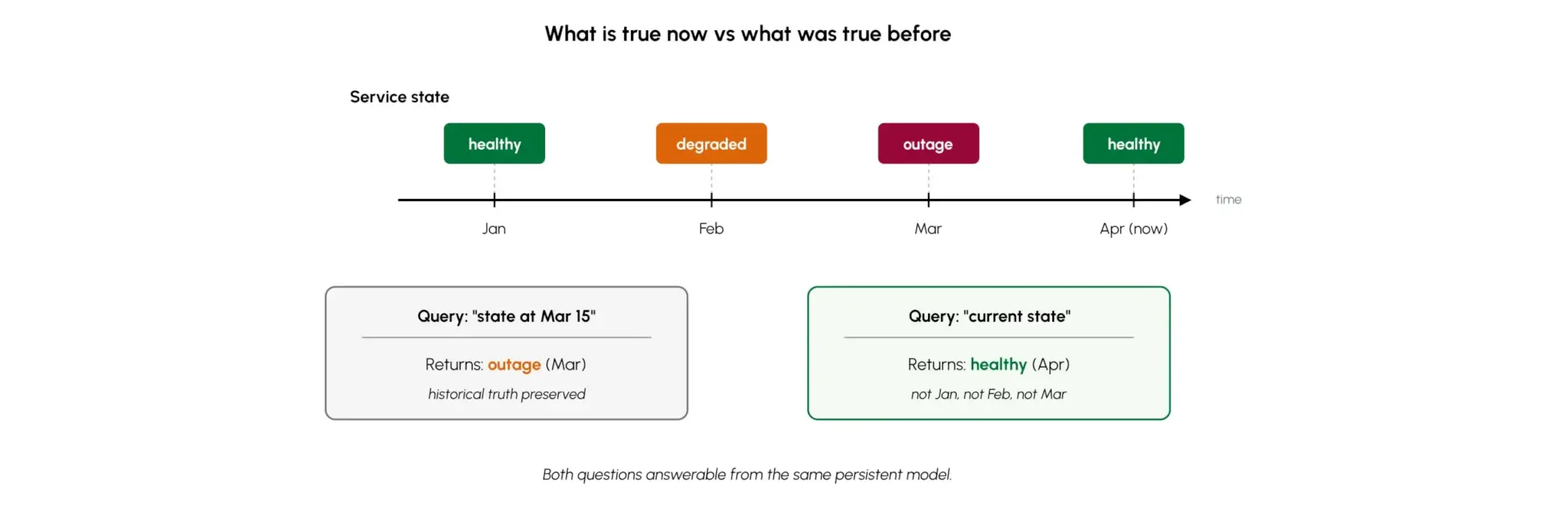
Time is the thing most AI systems handle worst. The index was built last quarter; the graph updates nightly; the warehouse lags a day. Agents reason across this drift and quietly produce wrong answers. Persistent context carries an evolving state rather than reconstructing it. Bi-temporal modeling tracks both when an event occurred (valid time) and when it was recorded (transaction time) — so “what is true now” and “what was true at time T” come from the same model.
Valid time
when it happened in the world
Transaction time
when the system learned about it
Query at T
state as-of, or state as-known-at
What this gives you
Awareness of current vs. historical state
Tracking of changes, sequences, and events
Time-aware querying and reasoning
In Arango
AutoGraph continuously updates the graph as data changes. No manual refresh required
AQL queries any point in time: current state, historical state, or the delta between them
Temporal context is built into the data model, not added as a logging layer
Failure mode
Freshness gaps between stores mean agents answer “what is true” with stale state. Reconciling a warehouse-lagged record against a live graph requires ad-hoc reconciliation code — which itself becomes stale.
Historical queries (“what did we know on March 3rd?”) are almost always impossible without rebuilding from logs.
How Arango solves it
Arango tracks two things simultaneously: what is true in the world right now, and what the system knew at any given point in time.
That means you can query the actual state of a customer, service, or incident at any moment in history — not just what was recorded, but when it was recorded. AutoGraph ingests continuously, so freshness is a structural property of the platform — not an operational scramble after the fact.
Requirement 04
Provenance & trust
All data must be traceable, governed, and explainable.
An AI output without lineage is not defensible. A SOC 2 audit, an EU AI Act review, or a regulator asking why a customer was denied all require the same thing: traceability back to source.
Every output
Carries a citation set traceable to source records
Every field
Access-controlled at the engine, not the API gateway
Every write
Logged with source, timestamp, and transformation chain
Every query
Emits an explainable plan alongside its results

What this gives you
Source attribution on every AI output
Field-level access control, enforced in the engine
Audit-ready logs across queries, edits, and ingests
In Arango
RBAC, audit logging, and lineage built in
Query traceability across AQL execution
Compliance-ready deployment modes (incl. air-gapped)
Failure mode
When provenance lives outside the data layer, it goes stale within weeks. Pipelines fork, records get re-derived, and the lineage graph diverges from reality. Audits then require forensic reconstruction — engineers reading commit logs to explain why a model cited a document that no longer exists.
How Arango solves it
Lineage is captured at write time and at query time. Every record carries source, ingest timestamp, and transformation chain; every AQL execution emits a query plan and citation set returned alongside results. RBAC is enforced at document, edge, and field level. Audit logs are immutable and exportable for SOC 2, ISO 27001, HIPAA, and EU AI Act review.
Requirement 05
AI-native service layer
Context must be directly consumable by AI systems.
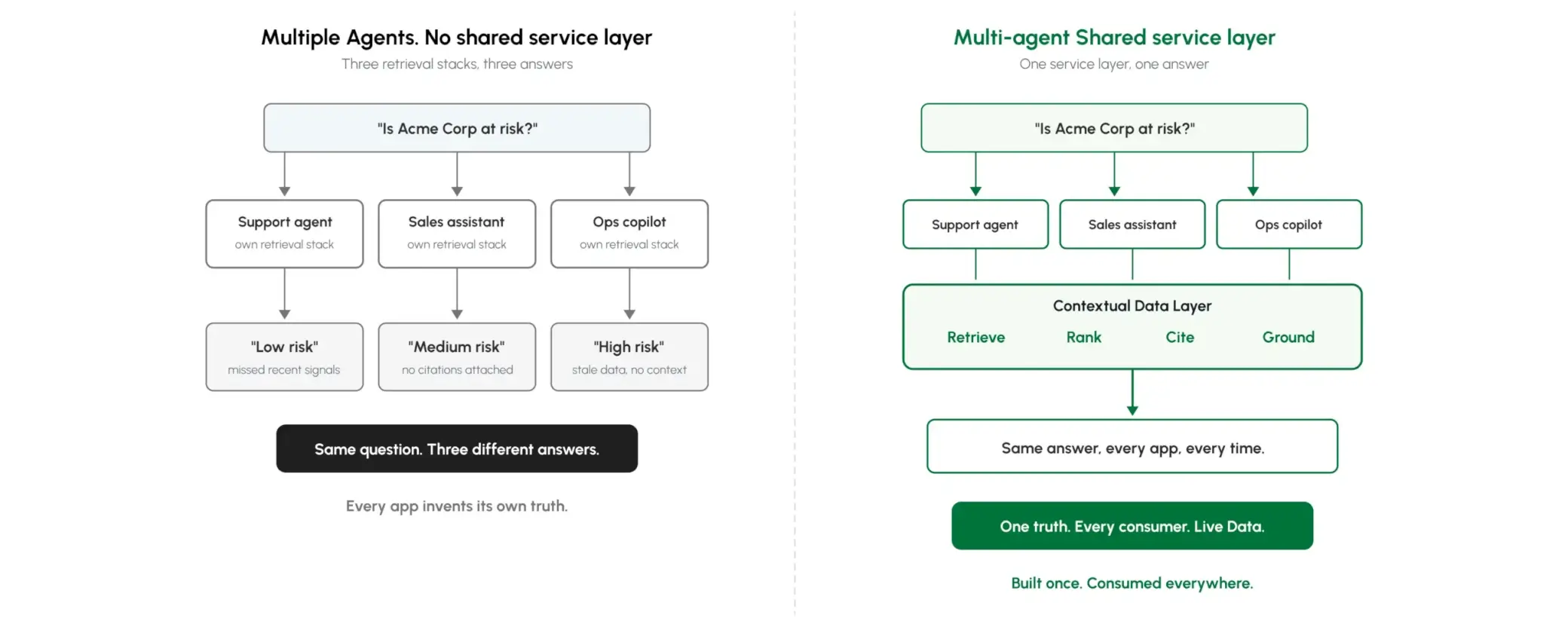
Most teams underestimate this one: they build a perfectly good context store, and then every AI application re-implements retrieval, ranking, citation, and grounding on top. The service layer makes those four verbs platform primitives.
Retrieve
Pull relevant context adaptively — graph, vector, or hybrid per query.
Rank
Order results by relevance, recency, and graph distance in one pass.
Cite
Return source IDs and traversal paths alongside every response.
Ground
Give agents the data and the explanation, not just the answer.
What this gives you
Every agent retrieves, ranks, cites, and grounds answers from the same platform layer. No custom retrieval code per application.
Agent-ready interfaces via MCP, native APIs, and direct integration
The right retrieval strategy selected automatically for every query
In Arango
AutoGraph determines the optimal ingestion approach and graph structure per data domain — so your context graph is retrieval-ready from day one
Deep Search decomposes each query into targeted subqueries and selects the appropriate RAG strategy for each GraphRAG, HybridRAG, or VectorRAG for optimal results
MCP server, native APIs, and BYOC (Container, Code) for teams bringing their own models
Failure mode
When every application reimplements its own retrieval stack, retrieval logic forks across the org. Different chatbots return different answers to the same question because each one tunes chunk size, top-k, and re-ranker independently. Citation drift sets in; the audit trail no longer agrees with itself.
How Arango solves it
The service layer exposes retrieval, ranking, citation, and grounding through native APIs and an MCP server, so every agent and application consumes context the same way. Deep Search handles the hard part: it reads the intent behind each question, selects the right retriever (graph traversal, vector similarity, or hybrid), and returns a single governed response.
Requirement 06
Unified multimodel data platform
Context must be unified across all data types in a single model.
The mistake most teams make is assuming they have to pick one or two data representations and work around the limits of the rest. The Frankenstack tax — sync lag, no cross-model transactions, five access policies — is permanent.

| Model | Description |
|---|---|
| Graph | Native edges, multi-hop traversal in milliseconds |
| Document | Nested JSON, schema-flexible |
| Vector | Semantic similarity and nearest-neighbor search |
| Key-value | Low-latency state & lookups |
| + AQL | One query language spanning all four |

What this gives you
One platform, one query language, one governance model
Cross-model transactions and consistent reads
Lower operational and integration overhead
In Arango
Graph, document, vector, key-value, and search in one engine
AQL spans all four in a single execution path
Unified RBAC, audit logging, and lineage
Failure mode
Stitched stacks (Postgres + Neo4j + Pinecone + Mongo + Elasticsearch) carry a permanent tax: sync lag, no cross-model transactions, five credential sets, and application code fanning out and re-merging results on every request. Latency compounds; consistency degrades; the team runs a distributed systems project instead of an AI project.
How Arango solves it
Graph, document, vector, key-value, and search live in one data engine and share one query language. A single AQL statement can traverse a customer subgraph, filter by document fields, rank by vector similarity, and join to a key-value lookup — in one execution path, with one transaction boundary, one access policy.
Architecture defines requirements. Requirements define AI outcomes. Miss any of the six, and agentic AI will hit a ceiling no amount of engineering can fix after the fact.