Chapter 7
Why 2 of the 3 enterprise AI architectures hit a ceiling
Most enterprise AI architectures fall into one of three categories. Each solves the problem differently. Only one delivers all six requirements in a single system.
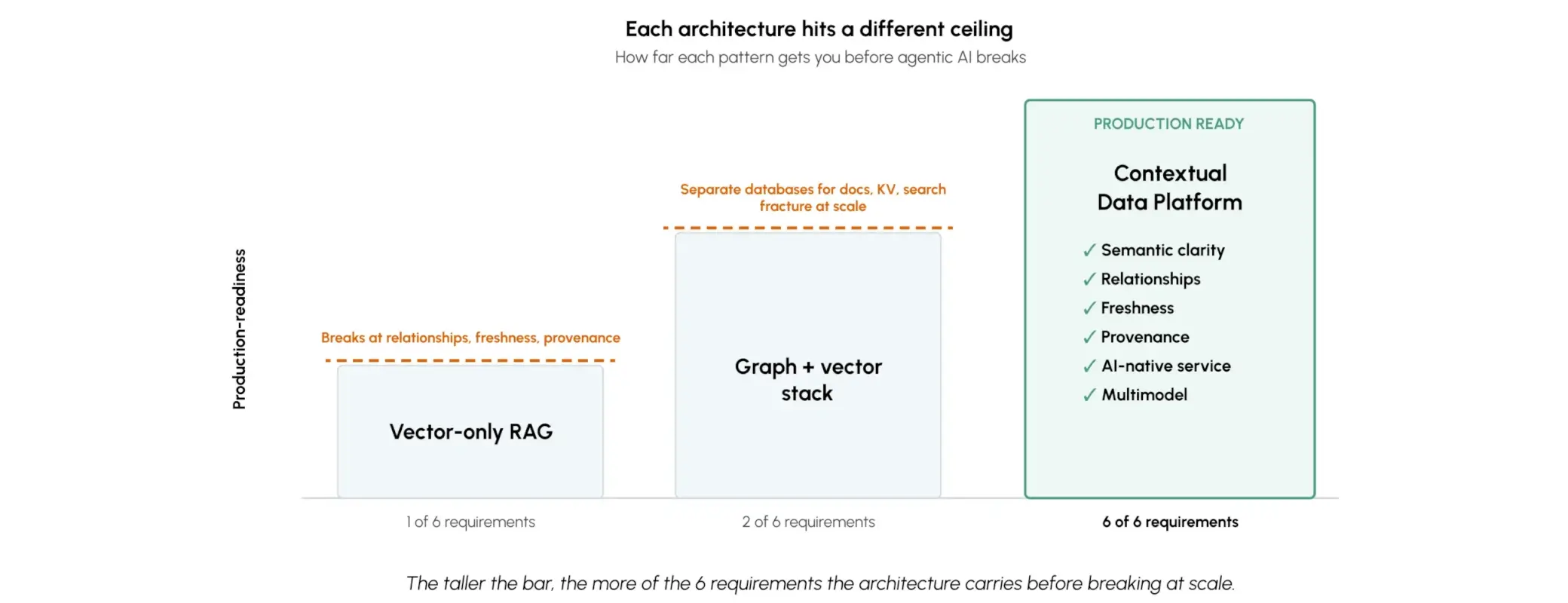
Scored against the 6 requirements
| Requirement | Vector-only RAG | Graph + Vector Stack | Contextual Data Layer |
|---|---|---|---|
| Semantic clarity | Embeddings only. No shared definitions. | Enforced for graph + vector. Document, key-value, search rely on upstream cleanup. | Shared entity definitions persist across all five models. |
| Relationships | Not modeled. Inferred from text similarity. | Native in graph + vector. Glue code into document and key-value. | Native alongside every other model. One query. |
| Freshness & time | Index refreshes on its own schedule. Stale. | Graph + vector share cadence. Rest drift at the seams. | Current and historical state in one model. No drift. |
| Provenance & trust | Source chunk is traceable. Reasoning is not. | Lineage holds inside graph + vector. Breaks crossing systems. | Lineage and RBAC unified across all five models. |
| AI-native service | Every app writes its own retrieval code. | Retrieval lives in LangChain-style glue once queries cross systems. | AutoRAG + MCP server built into the platform. |
| Multimodel coverage | One model. Vector. | Two models in one system. Rest live elsewhere. | All five: graph, vector, document, key-value, search. |
Key takeaway: Vector-only RAG and graph + vector both ship demos. Only a contextual data platform carries all six requirements in one system — which is what production agentic AI requires.

Objections worth taking seriously
01
Why not just use Postgres with pgvector?
Postgres with pgvector handles two of the five data models (relational and vector). Graph, document, and search live elsewhere — and the integration seams return.
02
Our graph database added vector support. Isn’t that enough?
Graph + vector is a real improvement over older graph-only architectures. It still leaves document, key-value, and search outside the system and re-creates seams at enterprise scale.
03
Why not wait for LLMs to get good enough that context doesn’t matter?
The gap is not the model. It is grounding. LLMs produce better answers when they have access to your specific data, relationships, governance, and policies — not generic training. That is what a contextual data layer provides.